[cb]: https://collectionbuilder.github.io/ "CollectionBuilder" ## Digitization of Text Documents John Walsh z652 Digital Libraries Dept. of Information and Library Science Luddy School of Informatics, Computing & Engineering Indiana University --- ## Text in Digital Libraries - As “texts” (books & journals) are in traditional libraries, digital texts are a dominant media type in digital libraries. - Early digital libraries, such as Project Gutenberg, were focused on digitized texts. - Digital text projects are often really multimedia projects in which digital text is combined with page images or auxiliary digital images of illustrations, graphs, charts, and other graphics found in the text.
## Example Projects - [The Chymistry of Isaac Newton](http://chymistry.org) - [The Blake Archive](http://blakearchive.org/) - [HathiTrust Digital Library](https://hathitrust.org) - [Perseus Digital Library](http://www.perseus.tufts.edu/) - [Project Gutenberg](https://dev.gutenberg.org) - [Internet Archive](https://archive.org)
## Example Projects - [The Algernon Charles Swinburne Project](http://swinburneproject.org) - [Indiana Magazine of History](https://scholarworks.iu.edu/journals/index.php/imh/index) - [Legacy Tobacco Documents Library](http://legacy.library.ucsf.edu) - [Petrarchive](http://petrarchive.org) - [TCP/EEBO](http://textcreationpartnership.org) - [The Victorian Women Writers Project](http://dlib.indiana.edu/collections/vwwp/) - [Vincent van Gogh: The Letters](http://www.vangoghletters.org/vg/) - [The Walt Whitman Archive](http://whitmanarchive.org)
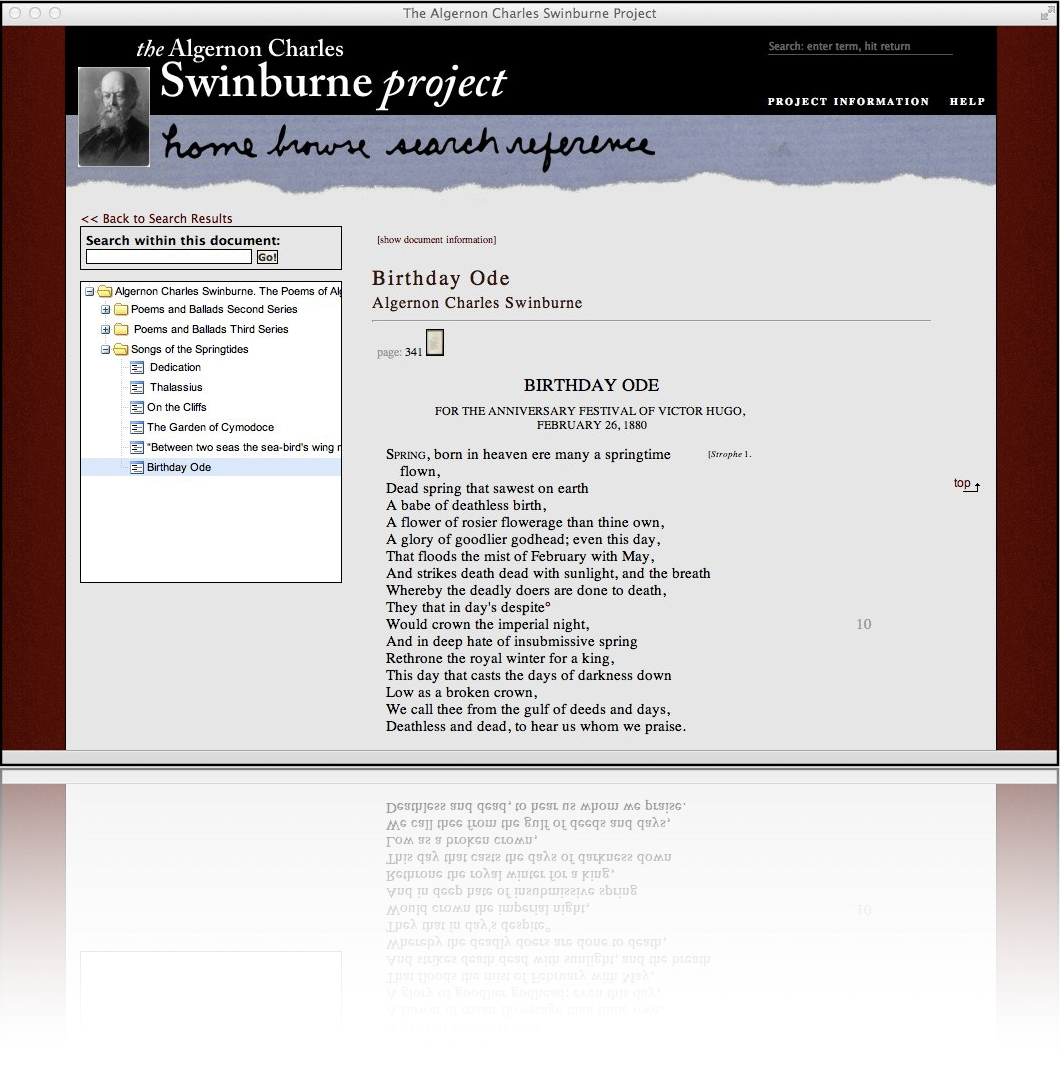
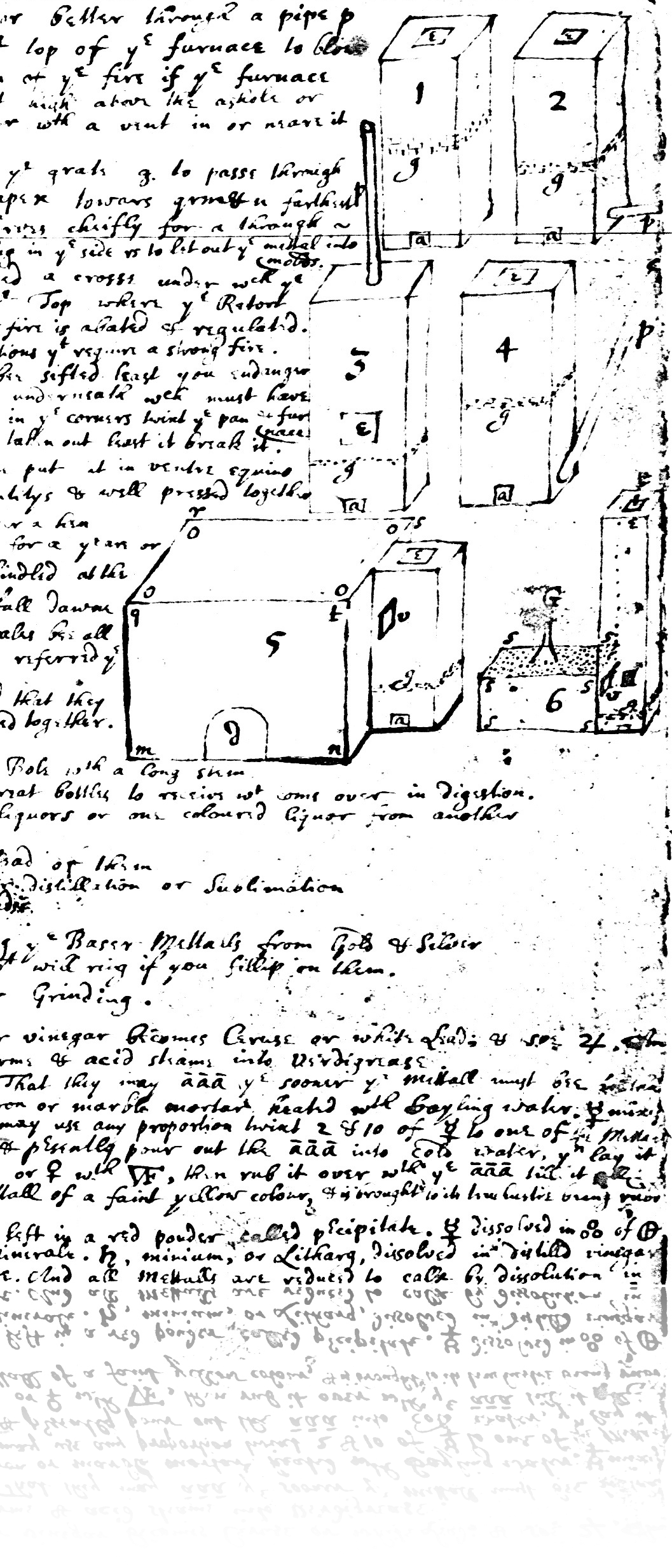
## Textual Document digitization process - Original document (book, manuscript, newspaper, microfilm, etc.) - scan or photograph original document - machine (OCR) or human transcription from images - transcription is optionally encoded for advanced search, display, and analysis. --- ## Textual Document digitization process  --- ## Textual Document digitization process  --- ## Textual Document digitization process  --- ## Textual Document digitization process 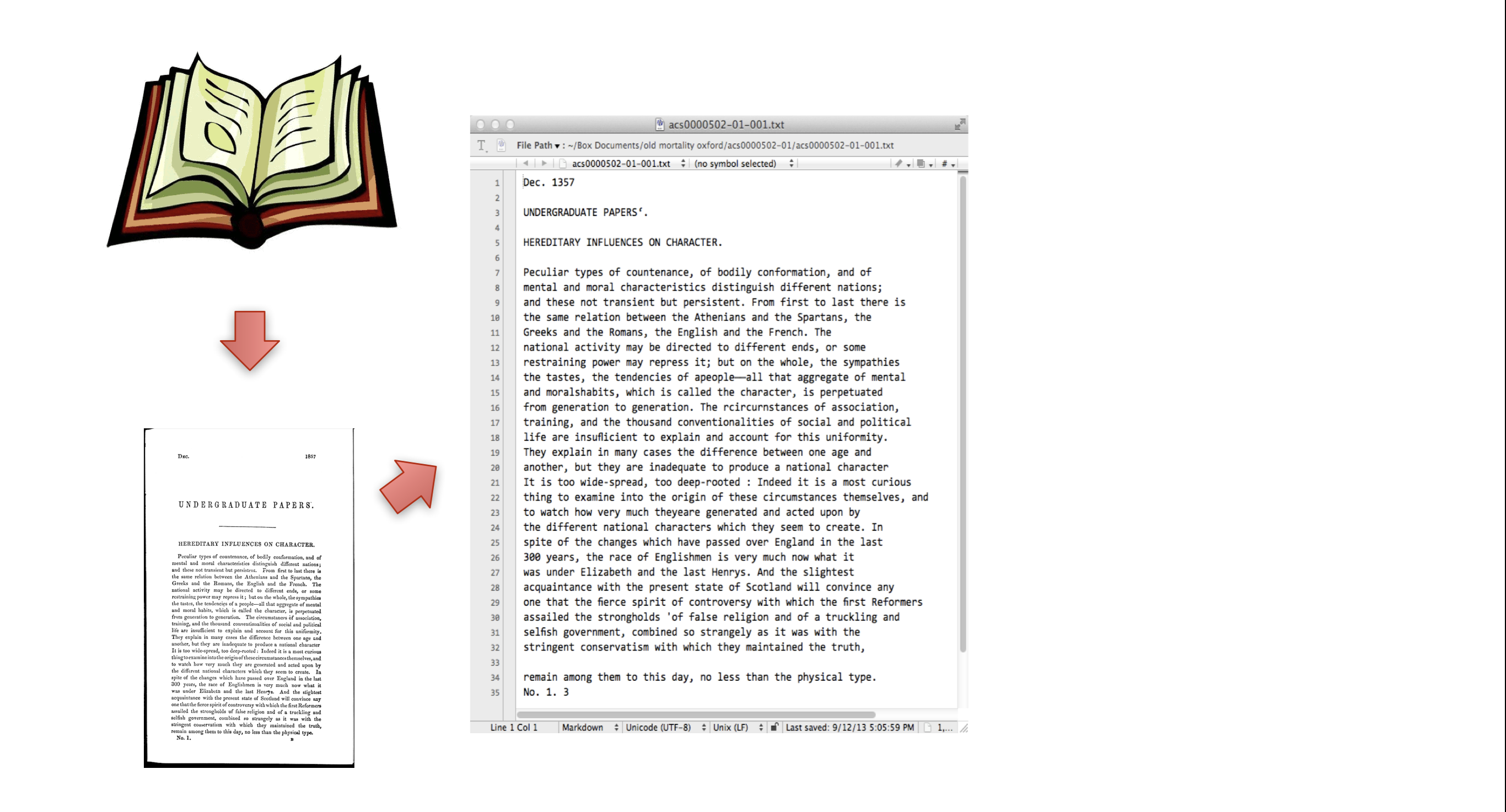 --- ## Textual Document digitization process 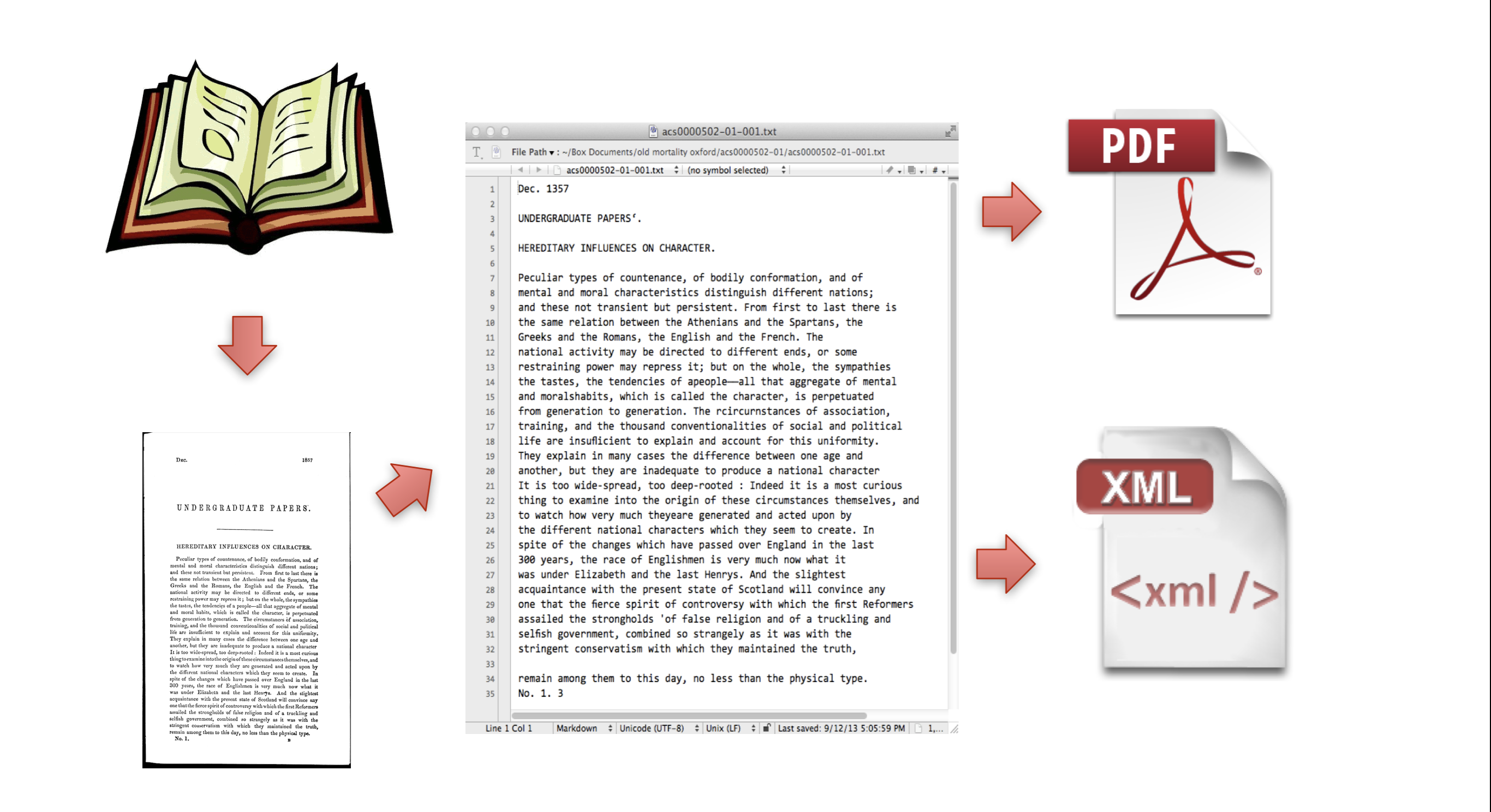 --- ## Textual Document digitization process 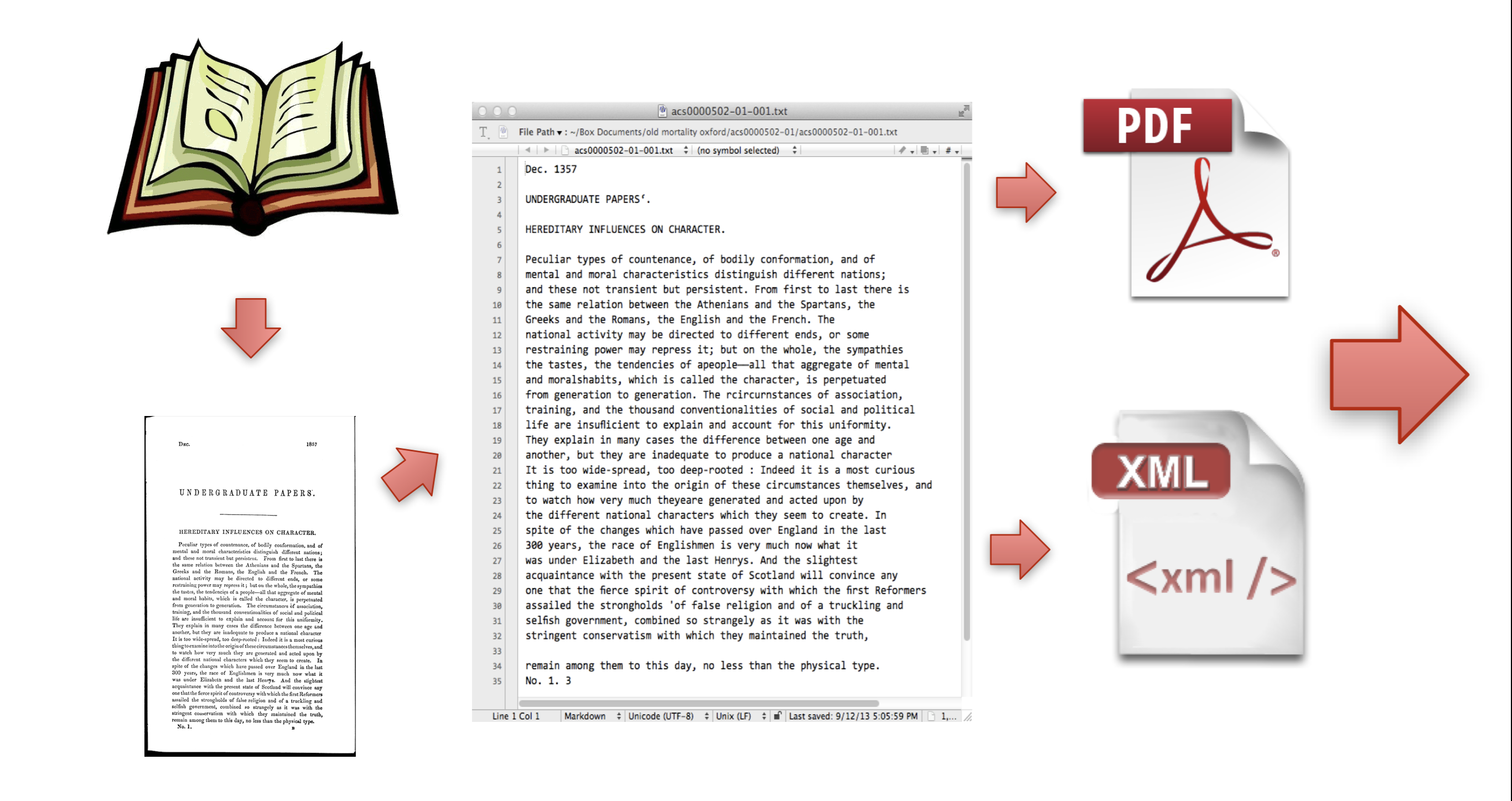 --- ## Textual Document digitization process 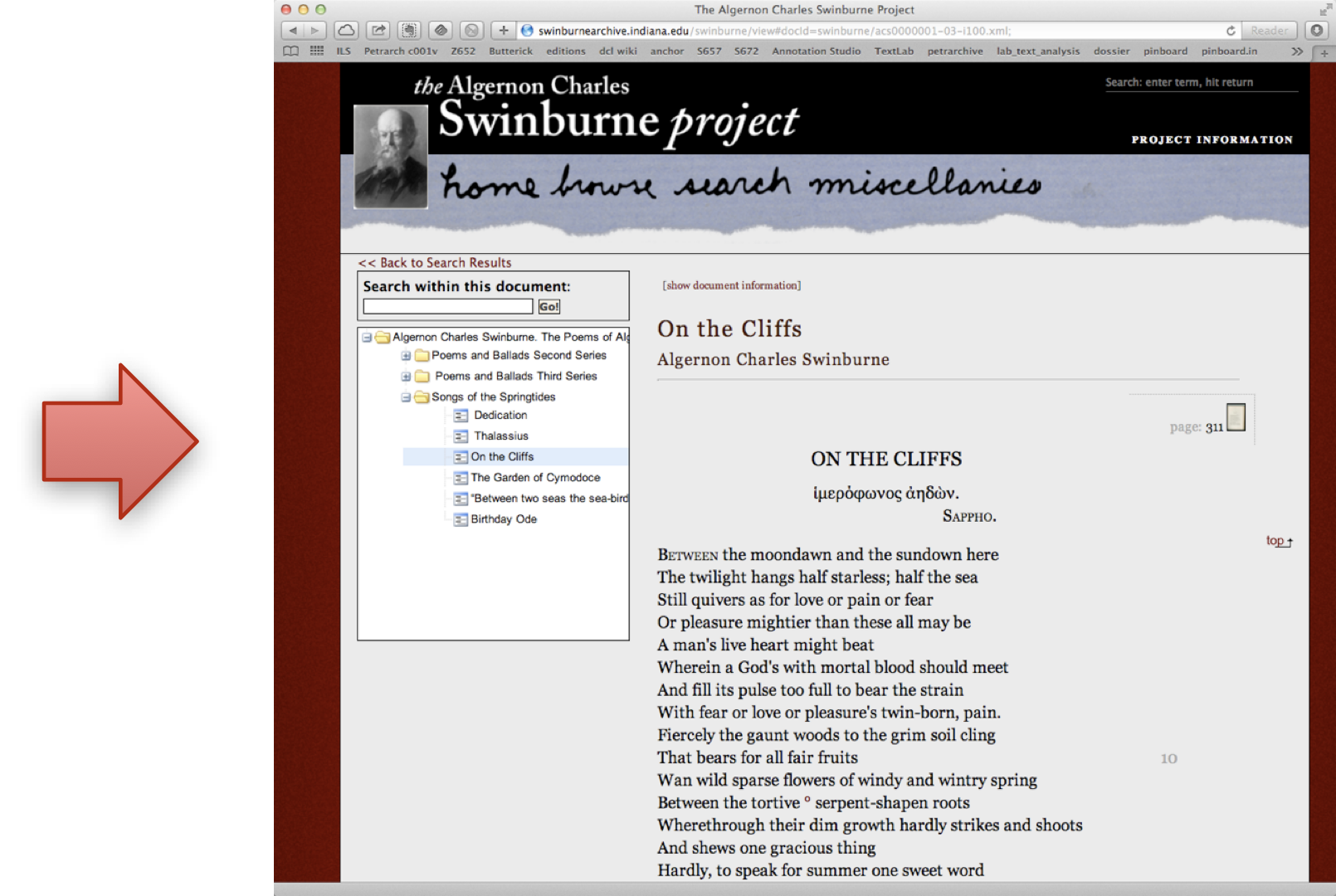 --- ## Images to Text: ### Machine Transcription, or ### Optical Character Recognition (OCR) - [ABBYY FineReader](http://finereader.abbyy.com) - [Tesseract](http://code.google.com/p/tesseract-ocr/) - [Prime Recognition](http://www.primerecognition.com) - [Adobe Acrobate](https://helpx.adobe.com/document-cloud/help/using-ocr-exportpdf.html#) --- ## Online OCR Services - [Adobe Acrobat](https://helpx.adobe.com/document-cloud/help/using-ocr-exportpdf.html#) - <https://www.newocr.com> - <https://onlineocr.net> - <https://ocr.space> --- ## Images to Text: ### Human Transcription - Human transcription is usually done by: - individuals or small teams (e.g., [Chymistry of Isaac Newton](http://chymistry.org/) or [VWWP](http://.indiana.edu/collections/vwwp/) - commercial vendors (e.g., [Aptara](http://www.aptaracorp.com/)) that transcribe massive amounts of documents using double-keying and triple-keying methods. --- ## Unicode, and other character encodings - A character encoding system, i.e., a system that maps characters to to some other representation, e.g, code points, or numbers, that the computer uses to represent characters. - ASCII, a common text encoding for “plain text” documents, has only 128 code points. Thus, it cannot possibly accommodate the thousands of characters used by historical, current, and fictional scripts and symbol systems. --- ## Unicode, and other character encodings [Unicode 15](https://home.unicode.org/announcing-the-unicode-standard-version-15-0/), the current version as of 2022-09-13, has: - 1,112,064 assignable code points - 149,186 characters from the 161 of the world’s scripts - 4,193 CJK (Chinese, Japanese, and Korean) ideographs. See: - <https://en.wikipedia.org/wiki/Unicode#Codespace_and_Code_Points> - <https://home.unicode.org/announcing-the-unicode-standard-version-15-0/> - <https://www.babelstone.co.uk/Unicode/HowMany.html> --- ## characters vs. glyphs 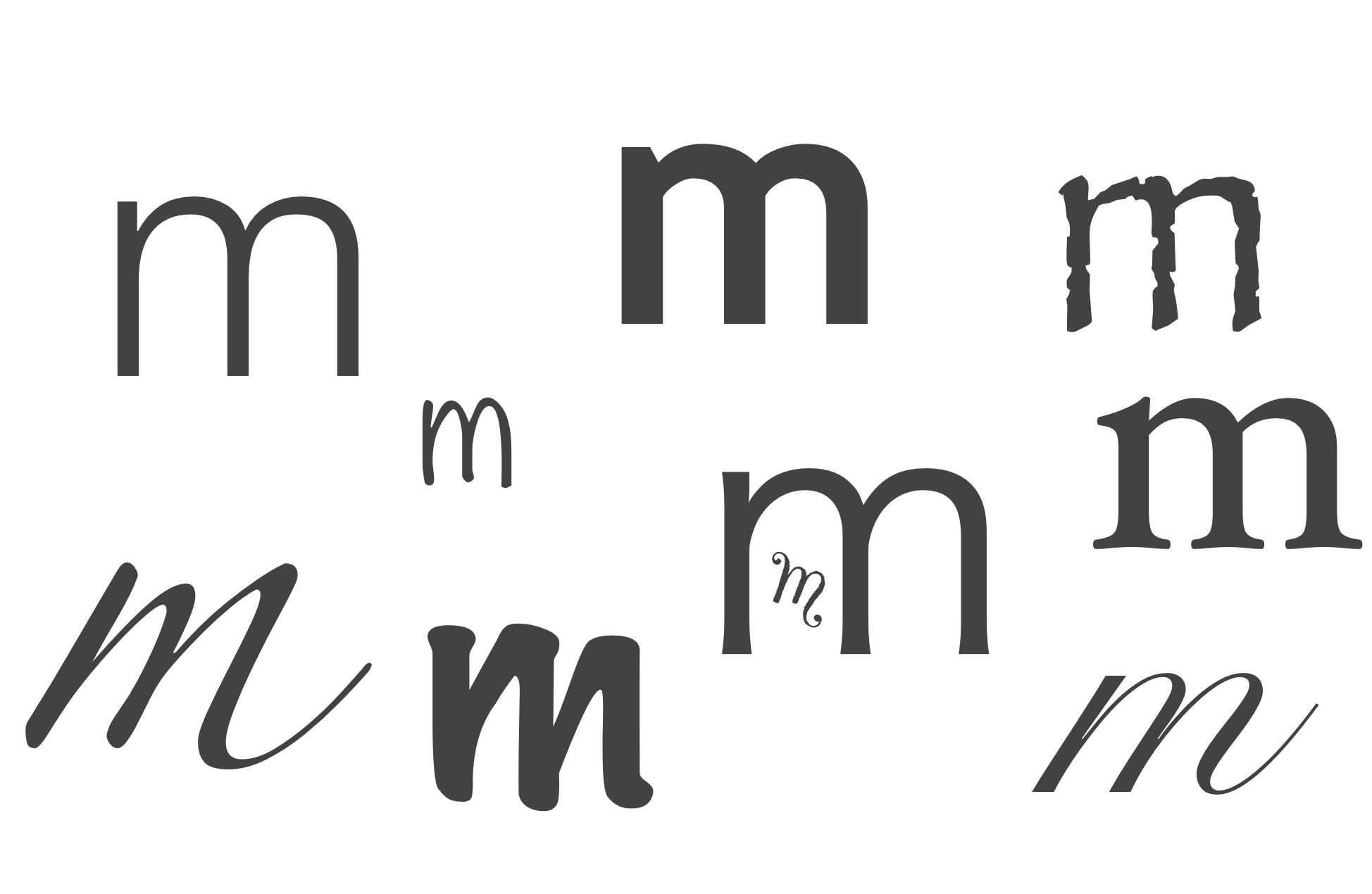 --- ## characters vs. glyphs 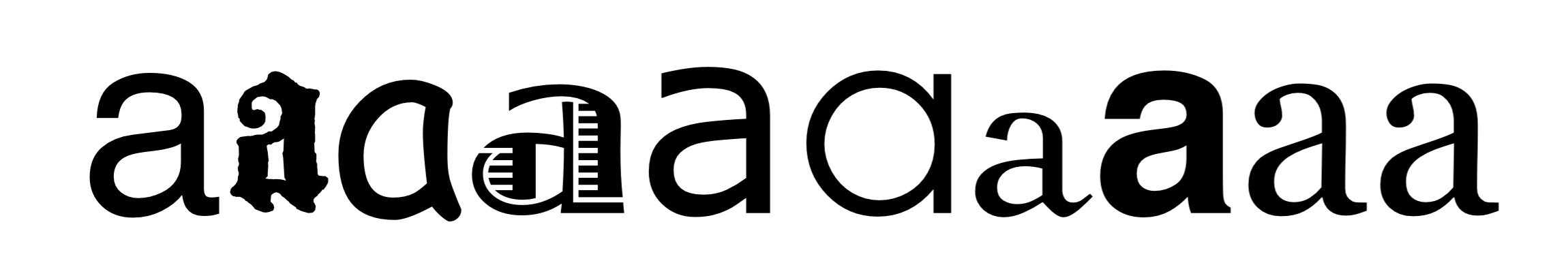 All the same Unicode code point: U+0061 --- ## characters vs. glyphs  Not the same code point: U+0076 and U+03BC --- ## Unicode encodings - The mappings between code points (numbers) to characters are consistent; however, there are various ways for computers to represent these code points numbers. - UTF-8 - UTF-16 - UTF-32 - UTF-8 is the most common Unicode encoding, and it is “ASCII-compatible”. For more information on Unicode encodings see: <http://www.unicode.org/faq/utf_bom.html> --- ## ASCII ### Character encoding 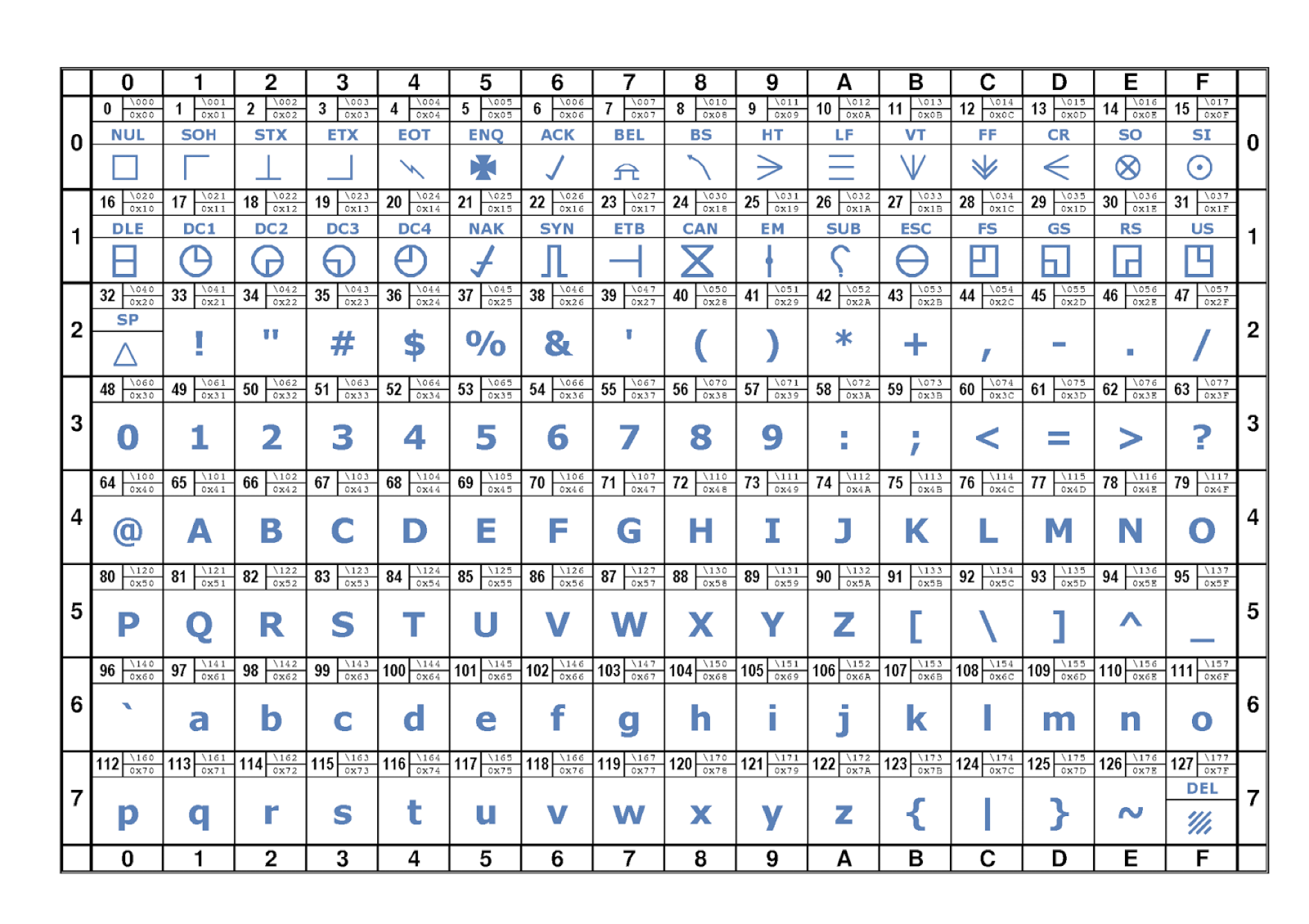 --- ## Alchemical symbols in Unicode <https://en.wikipedia.org/wiki/Alchemical_Symbols_(Unicode_block)> --- 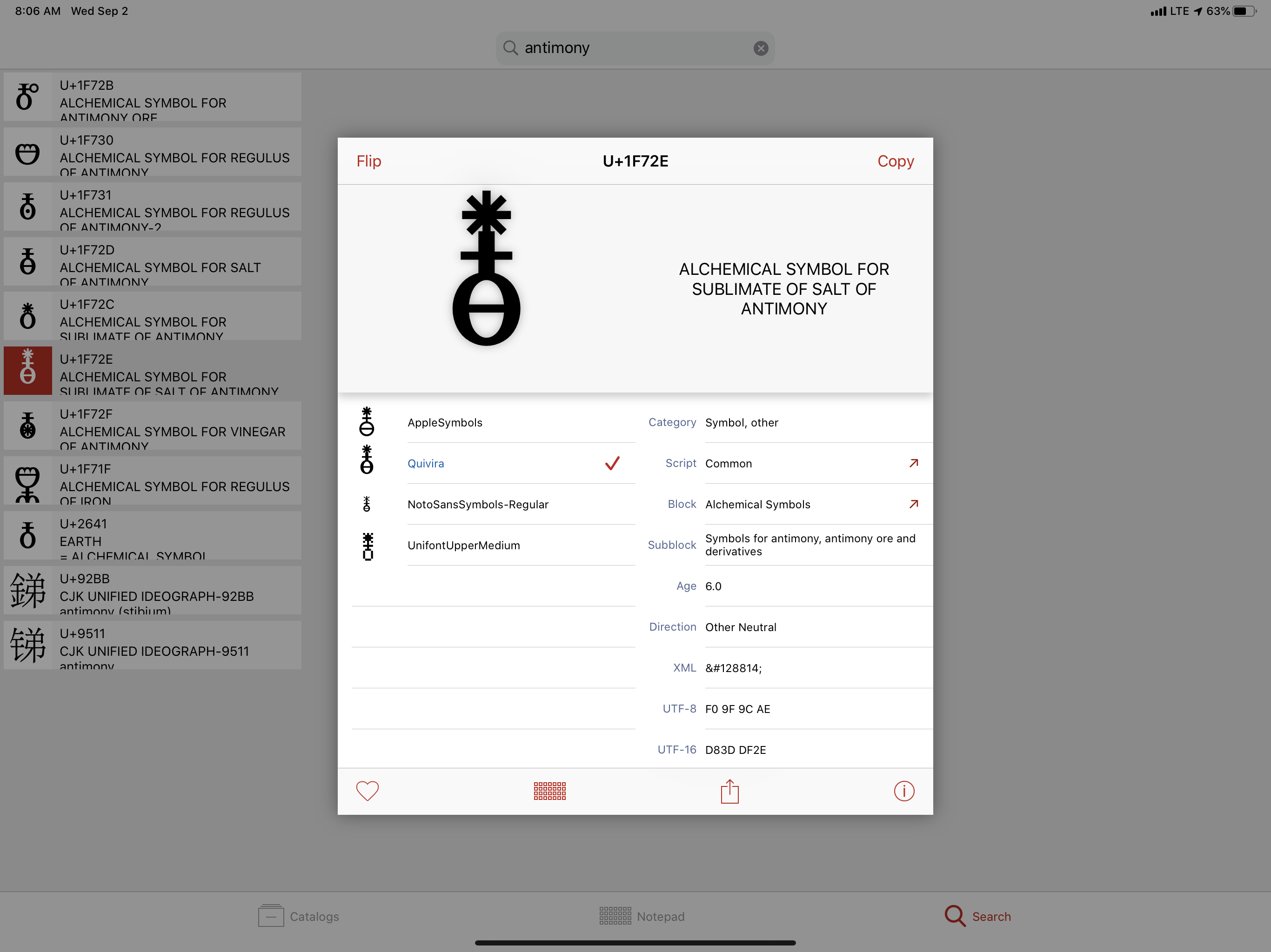
Alchemical symbols in Unicode
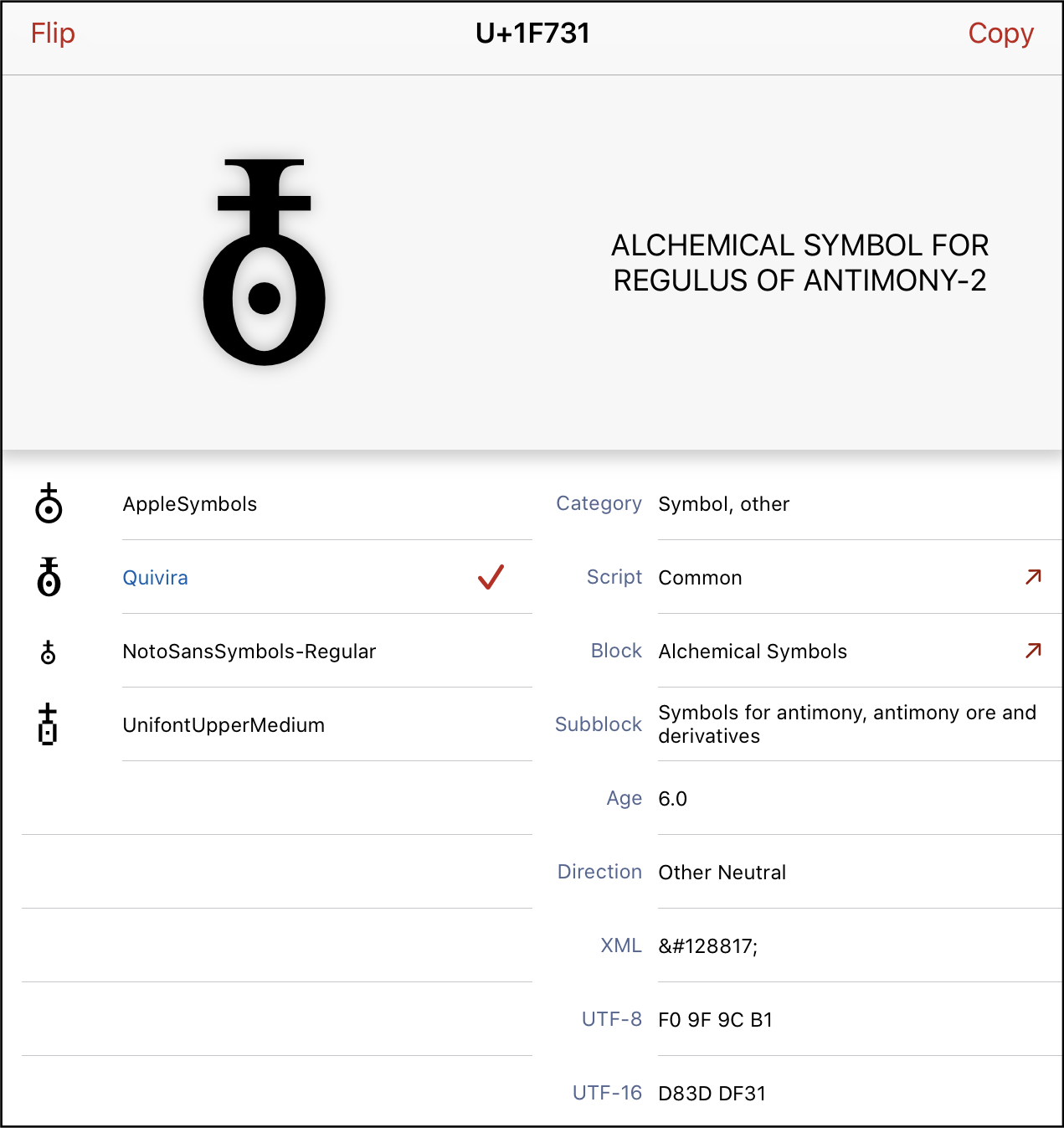
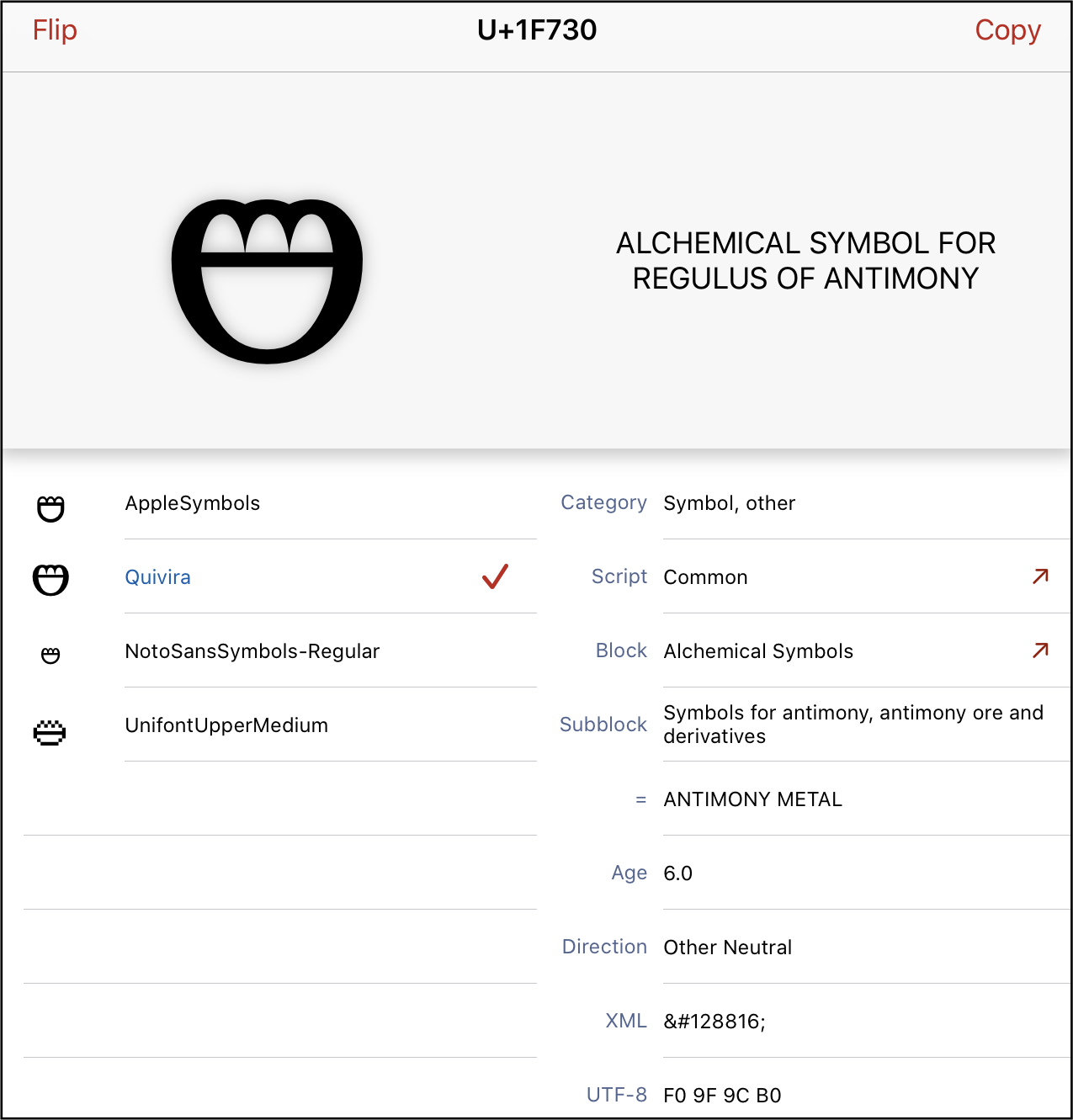
Alchemical symbols in Unicode
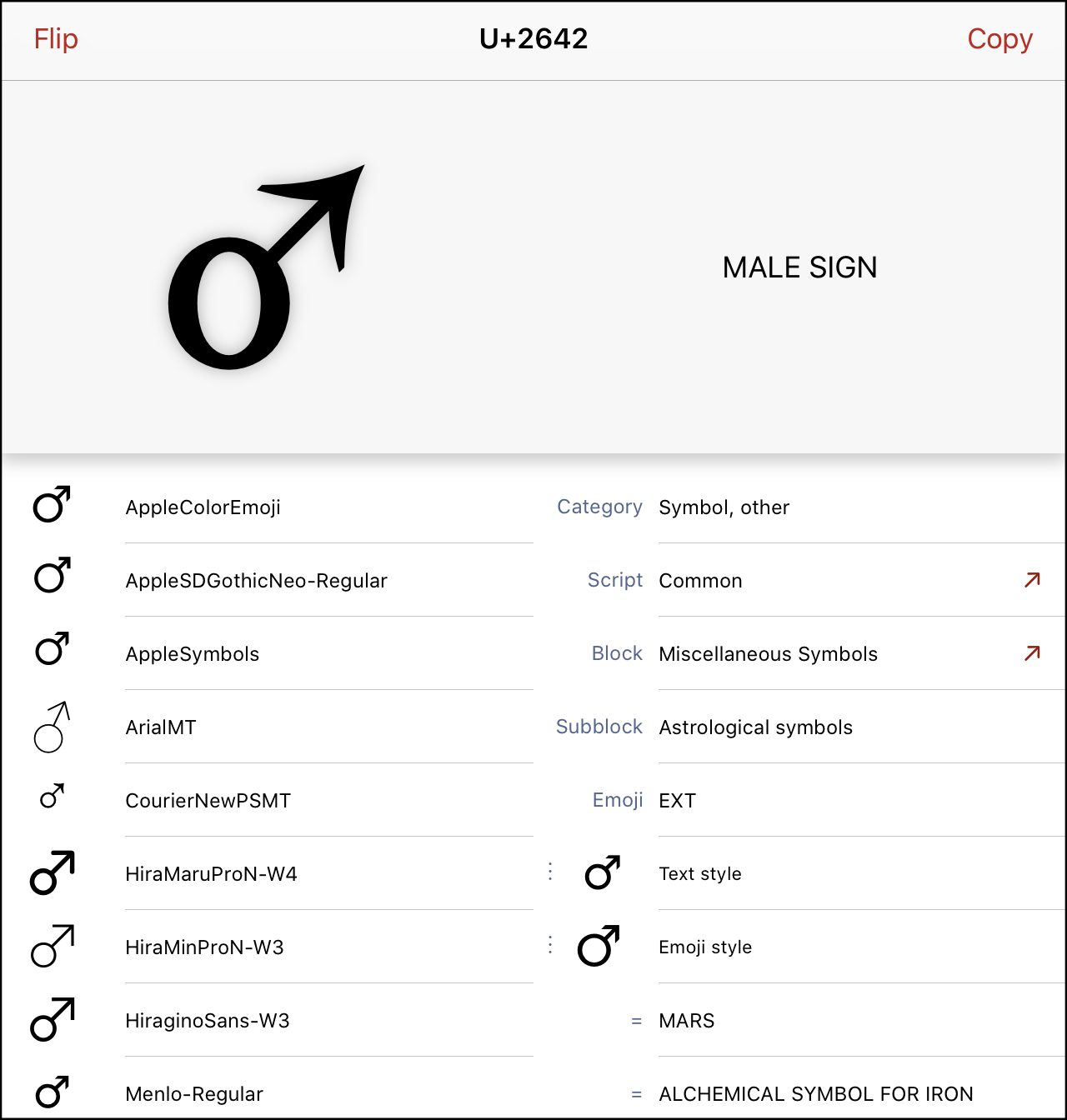
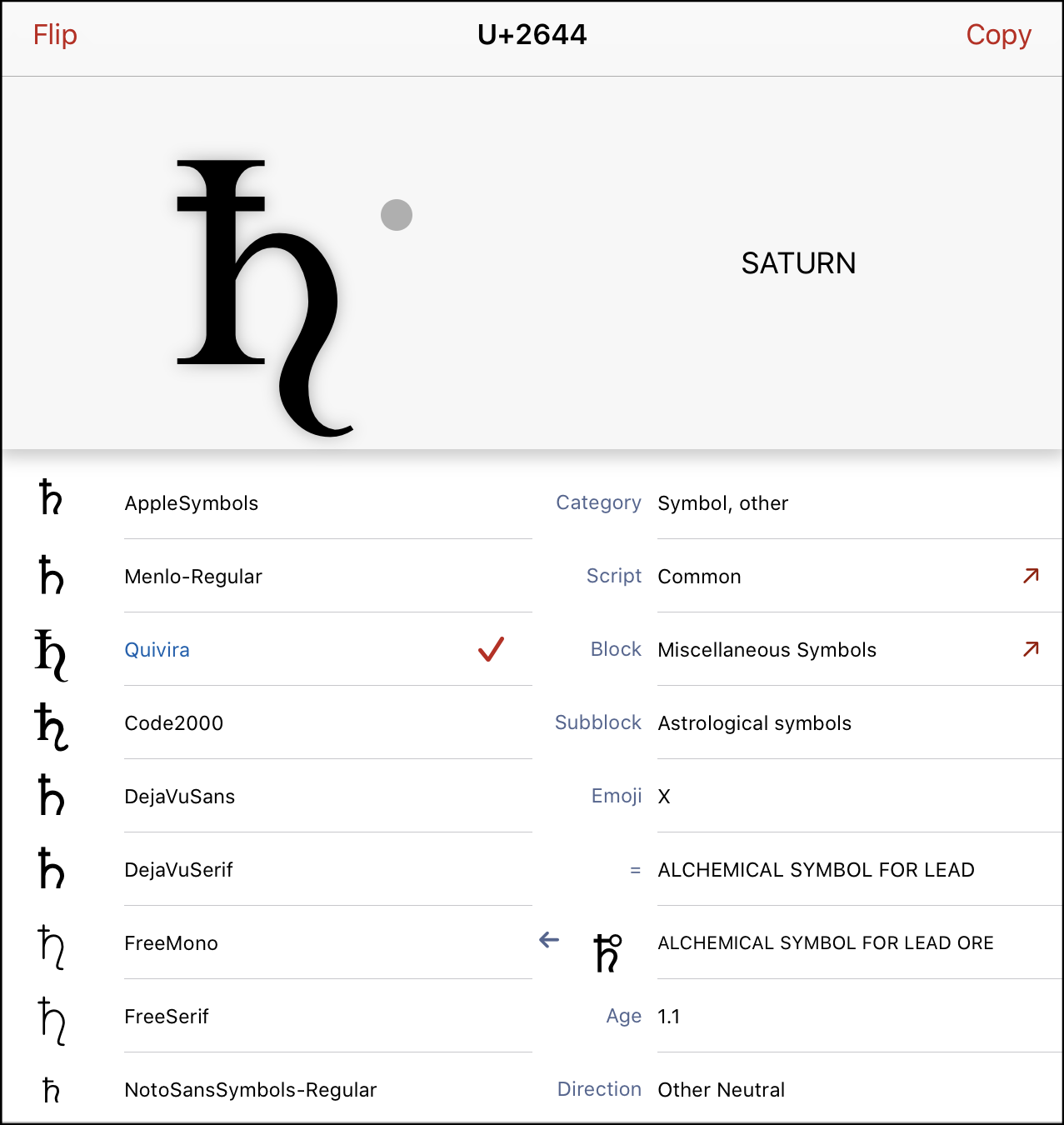
## Activity: Unicode reference apps Download and install a Unicode reference app, and find some interesting characters/character sets. - [UnicodeChecker](http://earthlingsoft.net/UnicodeChecker/) (mac) - <https://unicode-table.com/en/#nko> (web) - [BabelMap](http://www.babelstone.co.uk/Software/BabelMap.html) (windows) --- ## Identifying character sets and encoding - X/HTML - `<meta http-equiv="Content-Type" content="application/xhtml+xml; charset=utf-8" />` - `<meta http-equiv="Content-Type" content="text/html;charset=ISO-8859-1" />` - XML - `<?xml version="1.0" encoding="utf-8"?>` - `<?xml version="1.0" encoding="US-ASCII"?>` - HTML5 - <meta charset="utf-8" /> - `<meta charset="ISO-8859-1" />` --- ## Scanning and digitization equipment For availability of scanners see <https://servicenow.iu.edu/kb?id=kb_article_view&sysparm_article=KB0022502>